|
dots.tts 文本转语音项目
声音克隆 · 批量任务 · SRT 字幕配音 · 48kHz 高音质 · 全程离线
📌 这是什么
dots.tts 是小红书 开源的 2B 参数全连续自回归 TTS 模型,48kHz 采样率,零样本声音克隆效果在 Seed-TTS-Eval 等多个评测上达到开源第一梯队(中文 WER 0.94%)。
整合包本地离线,支持批量队列、音色库、SRT 字幕多角色配音。
✨ 功能特色
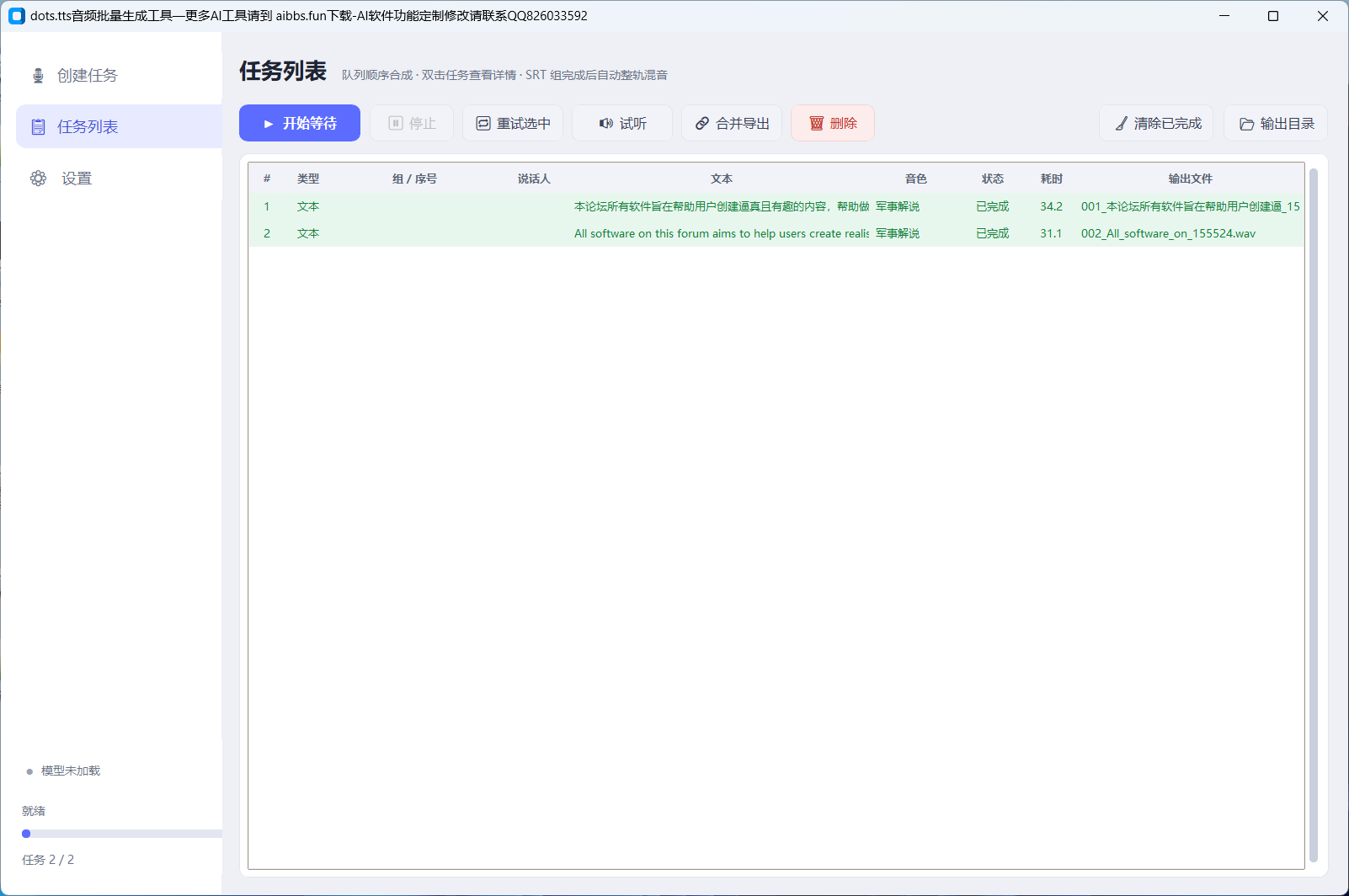
- 批量任务队列——任务逐条排队合成,状态实时显示(等待/处理中/完成/失败),支持单条重试、试听、删除;关闭软件队列不丢,重开自动恢复
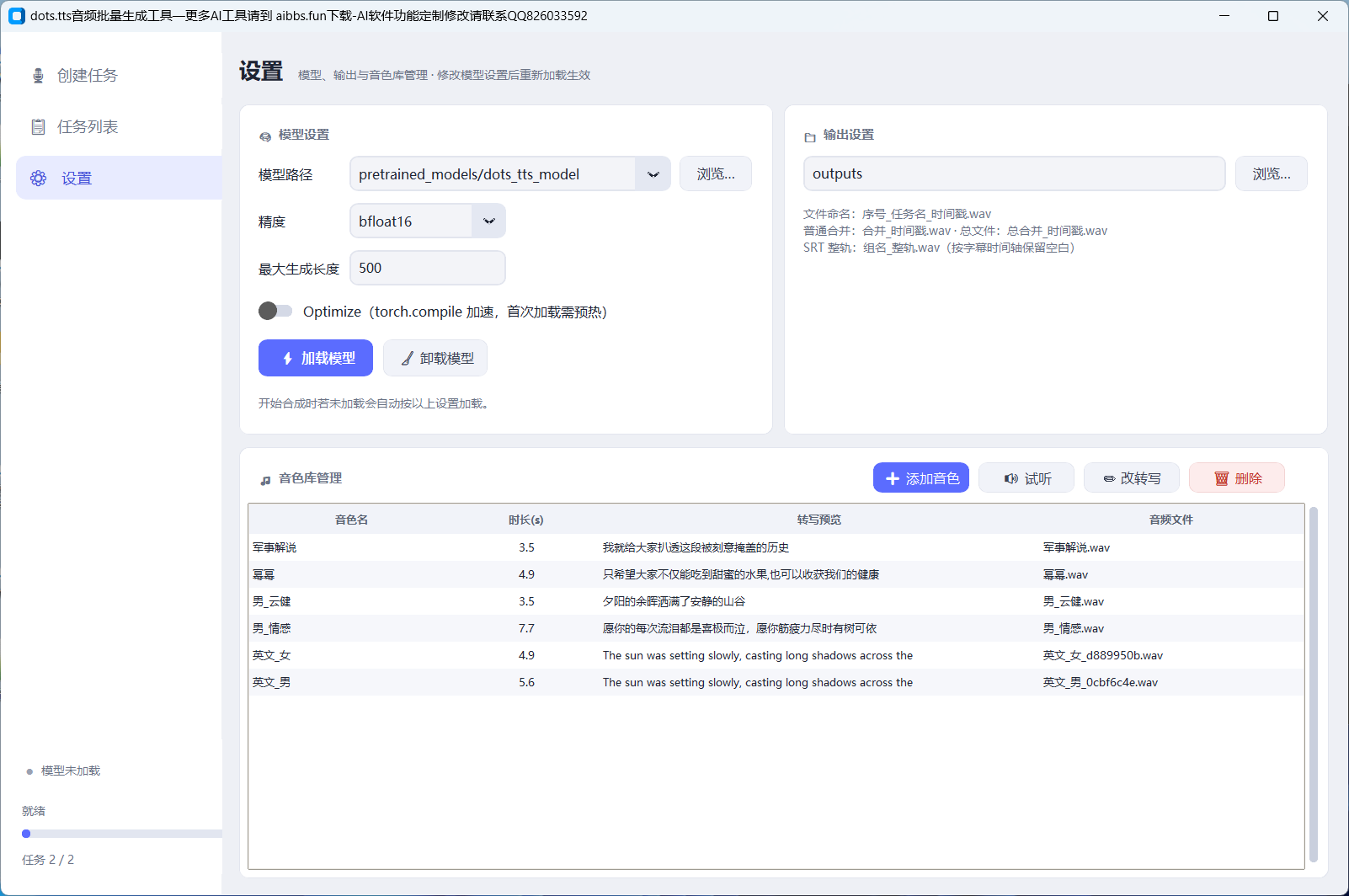
- 声音克隆——上传 3~10 秒参考音频+对应文字,即可用这个声音念任何文本;克隆好用的声音可一键存入音色库,下次直接下拉选择
- SRT 字幕配音——导入字幕文件按时间轴逐句配音,超长句自动 ffmpeg 变速压进字幕时间窗,全部完成后自动混成一条整轨音频,时间点和字幕完全对齐
- 多角色自动配音——字幕里写「张三:台词」,音色库里存过「张三」这个音色就自动绑定,没有的弹窗手动指派,做剧配音、视频解说极其省事
- 合并导出——批量任务可按顺序拼成一条完整音频(句间静音可调),导出前有清单面板预览会生成几个文件,还能再拼一个总文件
- 全程离线——整合包自带 Python 环境、ffmpeg、模型文件,启动器已锁死所有联网开关
🚀 三步上手
- 解压整合包,双击 启动.exe(首次合成时自动加载模型,约半分钟)
- 「创建任务」页:粘贴文本(或导入 TXT/SRT)→ 选音色(上传参考音频或选音色库)→ 点 ➕ 添加到任务队列
- 「任务列表」页:点 ▶ 开始等待,完成后试听满意的,不满意的选中重试(换个 Seed 再抽一次)
🎬 SRT 多角色配音教程
字幕文本支持三种说话人标记写法,任选其一:
- 1
- 00:00:01,000 --> 00:00:04,500
- 张三:今天我们聊一个有意思的话题。
- 2
- 00:00:05,000 --> 00:00:08,000
- [李四] 哦?什么话题,快说来听听。
- 3
- 00:00:08,500 --> 00:00:11,000
- <旁白> 两人的对话就这样开始了。
自动匹配规则:先在「设置 → 音色库管理」里把角色声音按名字保存(音色就叫“张三”“李四”),之后导入 SRT 时同名说话人自动绑定对应音色,全部匹配上连弹窗都不弹,直接添加任务开跑。
整组字幕合成完毕后自动按时间轴混音输出 文件名_整轨.wav,丢进剪辑软件和字幕严丝合缝。
🎛 参数速查
| 参数 | 默认 | 说明 | | Num Steps | 10 | 采样步数,越高越细腻越慢,10 已经很能打 | | Guidance | 1.2 | 引导强度,超过 2 音量能量会越来越大,不建议乱拉 | | Speaker | 1.5 | 音色贴近度,越大越像参考音频 | | Seed | 42 | 随机种子,同参数同种子=同结果;不满意点🎲换一个重试 | | 语言 | 不指定 | 支持 110+ 语言/口音标签(粤语、四川话、东北话都有) | | 文本规范化 | 关 | 数字、符号自动转读法,新闻类文本建议开 |
克隆小技巧:参考音频选 3~10 秒、干净无背景音的人声,并务必填写参考音频的文字转写(continuation 克隆模式),相似度明显高于只传音频。
💻 配置要求与实测
- 系统:Windows 10/11 64位
- 显卡:NVIDIA 显卡(CUDA),建议 8GB 显存起步;
- 输出:48kHz / 16bit 单声道 WAV
❓ 常见问题
- 问:不传参考音频能用吗?答:能,但底模是随机音色,每次声音都不一样,正经用法是配参考音频克隆
- 问:SRT 某句配出来比字幕时长长怎么办?答:软件自动调用 ffmpeg 变速压缩进时间窗,任务详情里能看到压缩比;压缩比太狠(>1.3)建议精简那句文案
- 问:任务失败了怎么看原因?答:任务列表里双击该任务,详情里有完整错误信息
- 问:模型放哪?答:整合包已内置 pretrained_models\dots_tts_model,也可以在设置页指向自己微调过的模型目录
dots.tts声音克隆工具,支持SRT字幕多角色配音,本地离线整合包
下载地址 :https://pan.quark.cn/s/1ed27fbd9ae8
解压密码: aibbs.fun
本工具免费分享,无任何使用限制,本地离线可用
声明:dots.tts 模型与代码均为 Apache-2.0 开源协议。声音克隆请勿用于伪造他人声音、诈骗等违法用途,AI 生成音频请显著标注。
| 


 窥视卡
窥视卡 雷达卡
雷达卡


 发表于
发表于 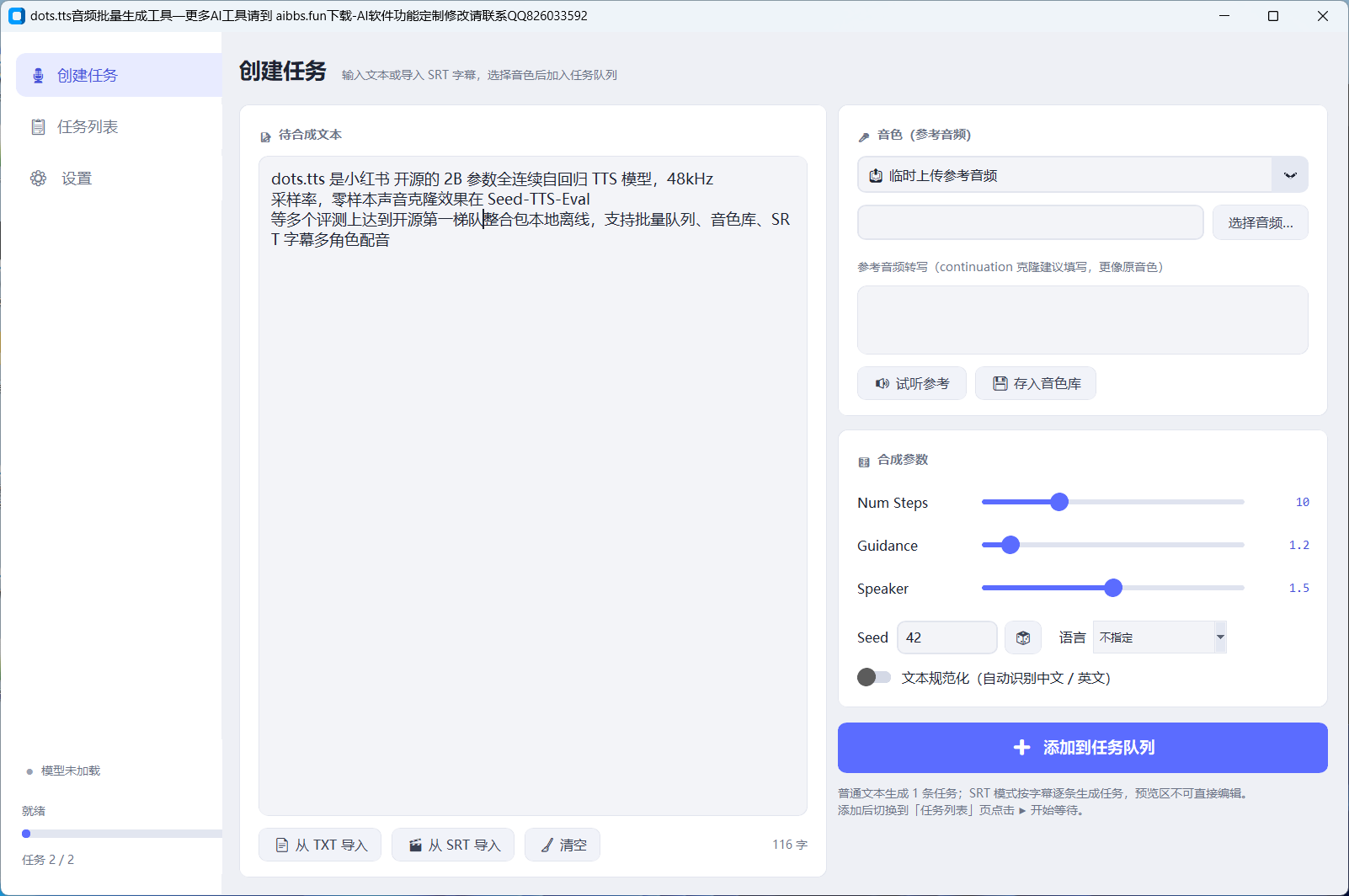
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜 发表于
发表于